Augmented reality has the potential to bring digital actions and information to the real world. But what user interface paradigms could help make this a reality? Here's some speculation and pointers to more.
For an augmented reality system to enable digital interactions with the real world, it would likely require the ability to:
- identify objects in the real world
- select objects in the real world
- choose and take actions on selected objects
- get results based on those actions
Adding digital objects in the real world and interacting with them is, of course, also possible but veers into Mixed Reality use cases. So for the sake of simplicity, I'm not focusing on digital object creation and manipulation... think more AR than VR.

Use Cases
What kinds of use cases could actually "augment" reality? That is, give people abilities they wouldn't otherwise have through the addition of digital information and actions to the physical world. Here's a few examples:



Identifying Objects
There's lots of things around us at all times which means the first step in identifying objects is breaking reality down into useful chunks. Meta AI's Segment Anything Model has learned a general notion of what objects are and can generate masks for any object in an image or video. When coupled with a visual captioning model like BLIP each of these object masks can be labeled with a description. So we end up with a list of the objects in our vicinity and what they are.
Selecting Objects
Once our field of vision (real time video) is segmented into objects and labeled, how do we actually pick the object we want to act on? One option is to rely on audio input and use it to search the object descriptions mentioned above. Imagine the following but with speech instead of text-based searching.
Another option is to allow people to simply point at the object they want to take action on. To do so, we need to either track their hands, eyes, or provide them with a controller. The later is what the LITHO team (I was an advisor) was working on. LITHO is a finger-worn controller that allows intuitive and precise gestures through a touch surface on the underside, a custom haptic feedback system and an array of motion-tracking sensors. Basically it allows you to point at objects in the real world, select, and even manipulate them.
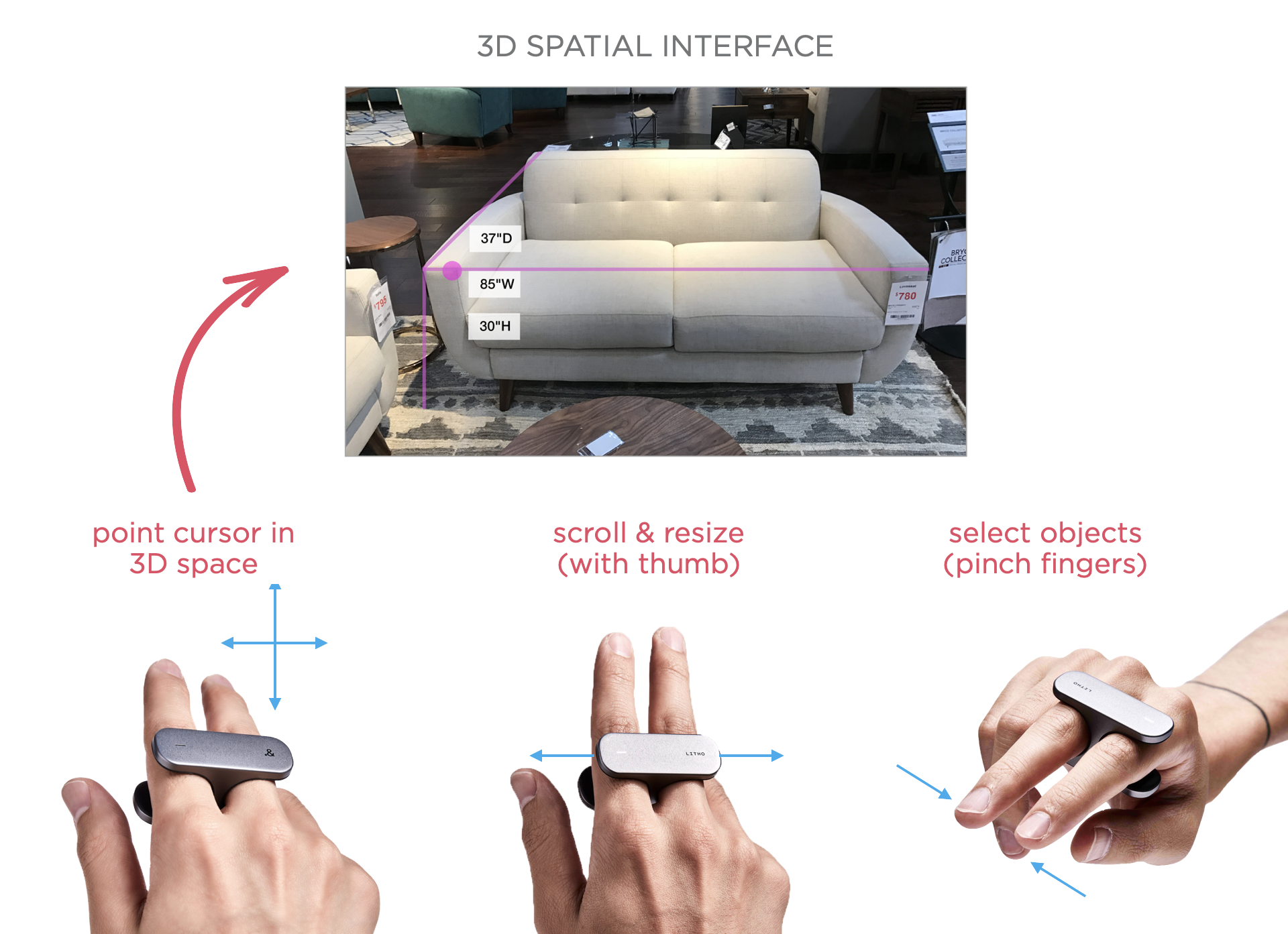
We can also detect and use eye gaze and/or hand gestures for selection and manipulation. For end users this usually means remembering discrete gestures for specific interactions instead of relying on physical controls (buttons, etc.). As you can see in the video below, the technology to detect even complicated gestures in real time has gotten quite good.
In all cases, we need to let people know their selection took effect. Several ways that could be done: pointers, outlines, masks, and more.

Taking Action
Now we've got the right object identified and selected... time to take action. While I'm sure there's been many "an app store for augmented reality" discussions, maybe it's time to boil things down to actions instead of full-blown apps. Most Web, mobile, desktop, etc. applications have loads of features, many unused. Instead of a store filled with these bloated containers, an augmented reality system could instead focus on the more atomic concept of actions: translate, buy, share.
Since we've identified and labeled objects, we can probably guess what actions are most likely for each, easing the burden on users to find and pick relevant options. Different entities could provide these actions too. Think: translate with Google, buy with Amazon, and so on. People could set their preferred provider as a default for specific actions if they choose too: "always solve with Wolfram Alpha".

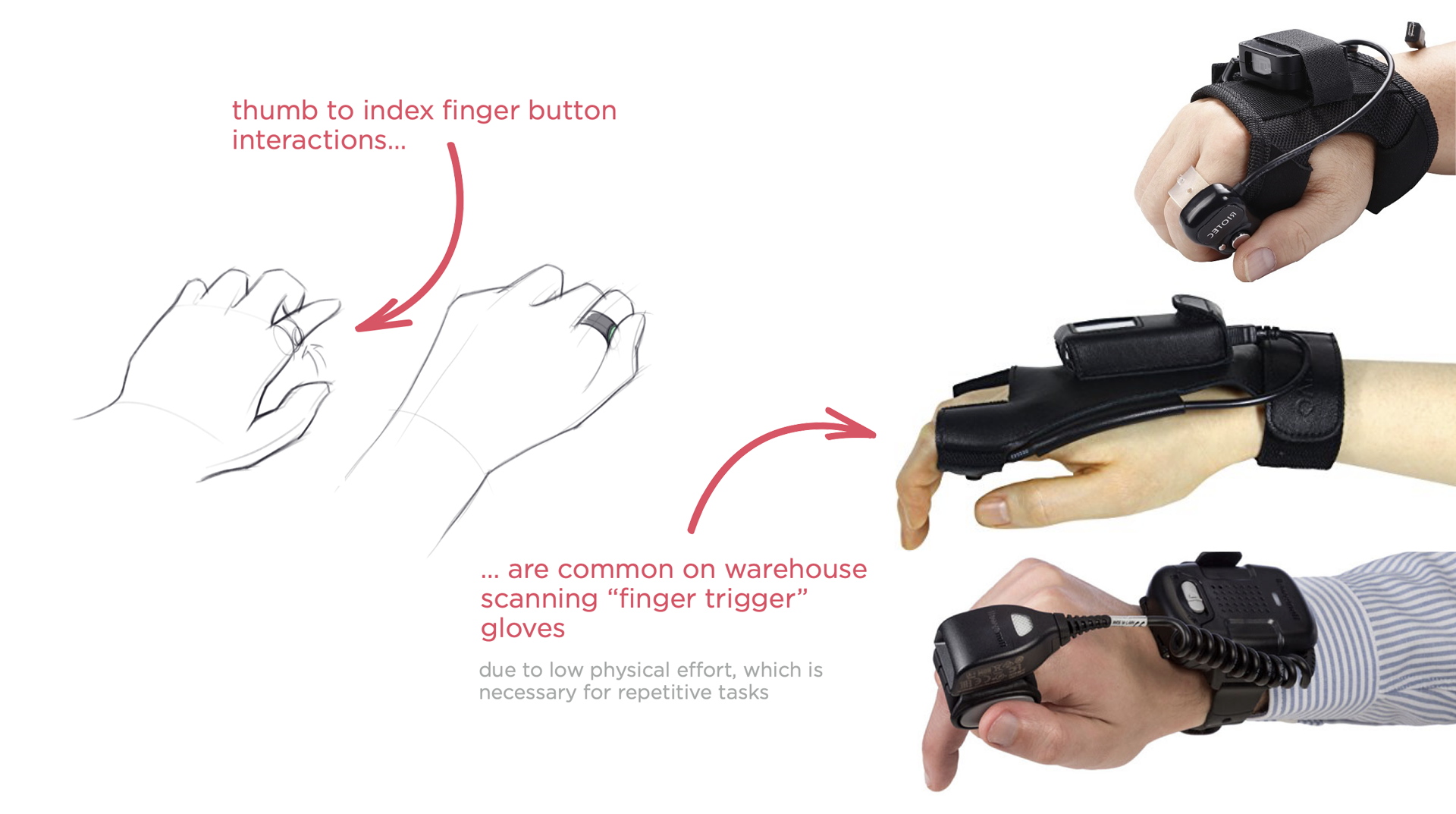
With all these actions available, how do you pick? Once again we can lean on speech, hand and/or eye gestures, or a minimal wearable controller. And again I kind of like the explicit intention you get from a hardware controller: press the button to talk, scroll the surface to browse, and so on -especially when conveniently located for one-thumb interactions.
Getting Results
So what happens when we take action on an object in the real world? We expect results, but how? Personally, I don't love the idea of plopping graphical user interface (GUI) elements into the real world. It feels like dragging along the past as we move into the future.
Direct object manipulation, however, has its limits so we're probably not done with menus and buttons just yet (sadly).
To go way back, the original Google Glass had a pretty cool feature: a bone transducer that amplified audio output so only you can hear it. Take action on an object and get audio responses whispered into your ear (pretty cool).
What will actually work best? We'll see...