I often use surfing as a metaphor for new technology. Go too early and you don't catch the wave. Go too late and you don't catch it either. Similarly next generation hardware or software may be too early for its time. I found myself wondering if this was the case for Google Glass and AI.
For those who don't remember, Google Glass was an early augmented reality headset that despite early excitement was ultimately shuttered. I spent time with the developer version of Google Glass in 2013 and, while promising, didn't think it was ready. But the technical capabilities of the device were impressive especially for its time. Glass featured:
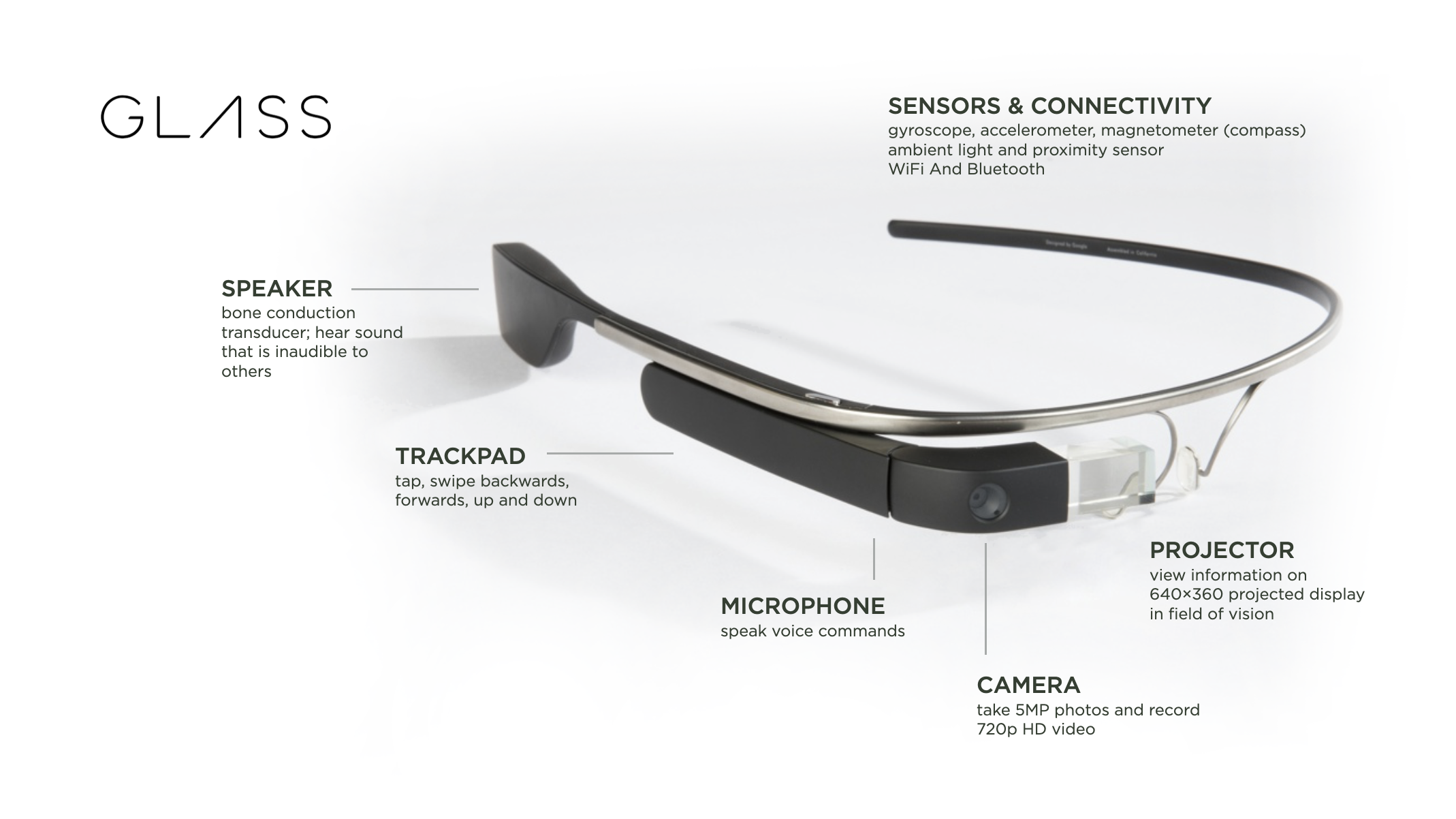
- a camera for taking photos and video
- a microphone for accepting voice commands
- a speaker for audio input only you could hear (bone conduction)
- a mini projector to display information and interface controls in the corner of your field of vision
- a trackpad for controlling the interface and voice commands
- a number of sensors for capturing and reacting to device movement, like head gestures
- WiFi and Bluetooth connectivity
What Google Glass didn't have is AI. That is, vision and language models that can parse and react to audio and video from the real World. As I illustrated in a look at early examples of multi-modal personal assistants: faced with a rat's nest of signs, you want to know if it's ok to park your car. A multi-modal assistant could take an image (live camera feed or still photo), a voice command (in natural language), and possibly some additional context (time, location, historical data) as input and assemble a response (or action) that considers all these factors.
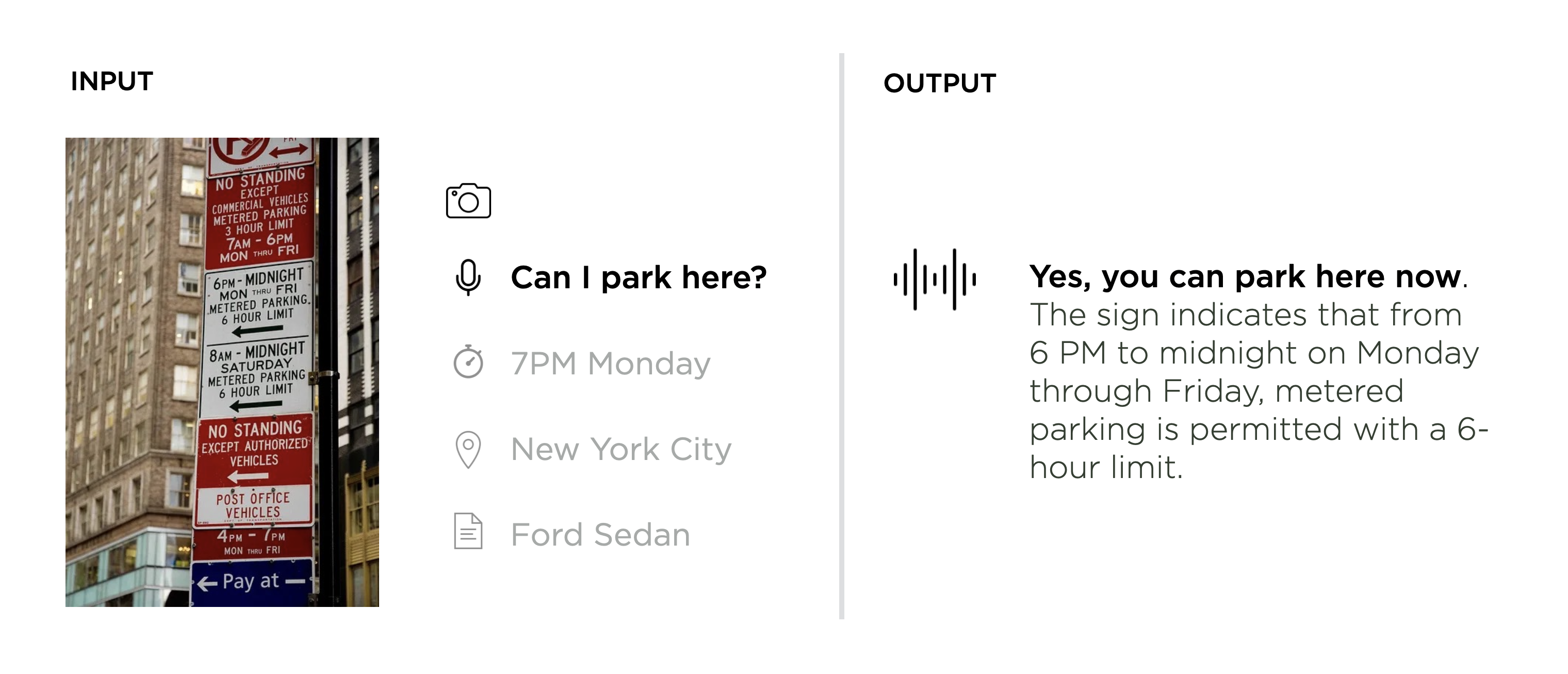
Google Glass had a lot of the technical capabilities (except for processing power) to make this possible in a lightweight form factor. Maybe it just missed the AI wave.